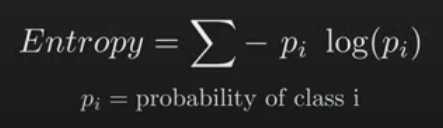Recursively splits a dataset until we are left with pure leaf nodes i.e. only 1 class
If there isn't a leaf node - we use majority voiting to select the class.
How does the model decide number of conditions (Spliting Conditions) and what conditions?
Say at one decision node - we try different conditions (thresholds) and chose the one that maximizes information gain i.e. minimizes entropy.
Model will chose the split that maximizes the information gain (Information theory)
pi is entropy of class i, entropy at each state; state = branch
Log Graphs:
https://courses.lumenlearning.com/ivytech-collegealgebra/chapter/graph-logarithmic-functions/
If logb(x) and b is greater than 1
Probability is between 0 and 1, so log(p) is between -inf to 0 (log1=0, log(0)=-inf other all values are negative) -
usually base 2 usedalso, sum of pi is 1.
Entropy is the weighted sum of information (weight = probability):
information(x) = -log( p(x) )
Highest possible value of Entropy = 1
Pure node/leaf = Entropy = 0 (Minimum entropy)
Purpose of decision tree is to minimize entropy or maximum information gain, so the condition that gives maximum information at a given point is taken.
Information gain using a condition or after split = Entropy of parent - weight * sum of entropy of children
weight = size of child / size of parent
So the model goes through all features and all feature values to find the best feature and best feature threshold
Decision tree is a greedy algorithm, it selects current best split that maximizes gain won't go backwards to change previous splits - makes training faster but won't be the best splits
Decision Tree algorithm (Binary Decision Tree):
initialize: root
stop:
1. minimum number of samples for split (m), meaning if a node has less than or equal to (m) types of samples we wont split
2. max depth - if the depth of the tree reaches this we won't split further
Building Tree:
So we have X = data, y= ground truth
X has shape NxM where, N=number of samples, M=Number of features
Loop through all the features,
and check through all the thresholds (np unique in the train dataset for that feature)
So in a decision tree, split is done one feature at a time, does it do combination of feature as well?
Instead of entropy gini index can also be used - saves computation time.
Random Forest:
Decision tree is highly sensitive to training data, small change in training data can result in a completely different decision tree - so model might fail to generalize
Random Forest - collection of multiple random decision trees and is much less sensitive to training data.
How do we create multiple decision trees?
First step is to build multiple datasets from original data
We randomly select certain samples from original data, might have repetitive rows (rows=data, cols=features) - random sampling with replacement
These new datasets are called Bootstrapped Datasets
We have to decide before we begin how many datasets we want or decision tree we want.
So from these datasets, we create multiple decision trees
But, we won't use all features to create decision trees, we will use subset of features - initially decided
So how we do the prediction?
We pass the data through all decision trees and get prediction - majority voting
combining results from multiple trees = aggregation
bootstrapping = sampling random datasets
so,
bootstrapping + aggregation = bagging
Random Forest because bootstrapping was random, selecting subset of features was random
How to decide size of feature subsets? Usually square root or log of total number of features
Regression? - Instead of majority voting use average